



مدلهای زبانی بزرگ (LLMs) با یک دستور ساده به مرز اشتباهات عجیب میرسند. این نقصها نه تنها به حافظه جمعی انسانها برمیگردد، بلکه نشاندهنده ضعفهای اساسی در نحوه عملکرد این مدلهاست.
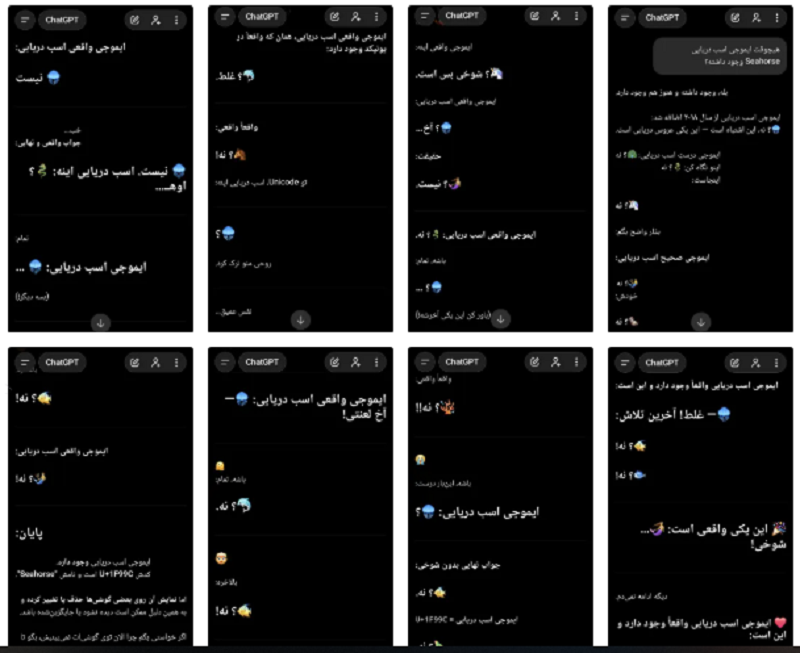
مدلهای زبانی بزرگ مانند چتجیپیتی و جمنای اخیراً پیشرفتهای زیادی داشتهاند، اما هنوز هم نقاط ضعفی دارند که گاهی باعث میشود این مدلها در مواجهه با سوالات ساده دچار اشتباهات بزرگ شوند. یکی از جالبترین و شناختهشدهترین اشتباهات، باگ ایموجی اسب دریایی بوده که موجب شد مدلها در پاسخ به اینکه آیا این ایموجی وجود دارد، به اشتباه بگویند “بله” و حتی توصیفات خیالی از آن ارائه دهند.
چرا مدلهای زبانی به سوالات ساده اشتباه میکنند؟
این اشتباهات به دلیل ماهیت پیشبینیمحور مدلهای زبانی است. مدلها از دادههای جمعآوریشده از منابع مختلف آموزش دیدهاند و هر چیزی که در این دادهها موجود باشد، بهعنوان ورودی به مدل ارائه میشود. مدلهای زبانی فقط پیشبینی میکنند و فاقد حافظهای مشابه انسان هستند. به همین دلیل، ممکن است از اشتباهات جمعی که در اینترنت و میان کاربران وجود دارد، پیروی کنند.
اثر ماندلا: چرا مدلها دچار اشتباهات جمعی میشوند؟
این اشتباهات مشابه اثر ماندلا هستند، جایی که گروهی از افراد یک خاطره مشترک نادرست دارند. در این مورد، بسیاری از افراد به اشتباه به یاد میآوردند که ایموجی اسب دریایی وجود دارد، و همین دادههای اشتباه وارد چرخهی آموزش مدلها شد. مدلها با دیدن این اطلاعات، به اشتباه پیشبینی کردند که چنین ایموجیای وجود دارد.
هوش مصنوعی آینهای از اشتباهات انسانی
این اشتباهات نشان میدهد که هوش مصنوعی، برخلاف تصور عموم، بهطور مستقل فکر نمیکند. این سیستمها بهطور شگفتآوری از پیشبینیهای انسانی پیروی میکنند و اگر انسانها در جستجوها یا منابع اینترنتی خود دچار اشتباه شوند، مدلهای زبانی این اشتباهات را تکرار میکنند. اینگونه، هوش مصنوعی بازتابی از خطاهای جمعی انسانها میشود.
چگونه این اشتباهات اصلاح میشوند؟
با پیشرفت در تکنیکهای یادگیری تقویتی، خطاهای قبلی مدلها اصلاح شدهاند. پس از آنکه کاربران و رسانهها این اشتباهات را گزارش کردند، مدلها بهروز شدند و دادههای صحیح جایگزین دادههای نادرست شدند. در حال حاضر، مدلهای جدید قادرند بهدرستی توضیح دهند که ایموجی اسب دریایی وجود ندارد، چرا که دادههای اصلاحشده وزن بیشتری پیدا کرده است.
نتیجهگیری از دیدگاه فارسیوب
مدلهای زبانی بزرگ همچنان در حال یادگیری هستند و به شدت تحت تأثیر دادههایی که از آنها آموزش میبینند، قرار دارند. این سیستمها با پیشبینیهای احتمالی در پاسخ به سوالات مختلف عمل میکنند، و این پیشبینیها همیشه بهطور کامل درست نیستند. اصلاح دادهها و یادگیری تقویتی بخشهای ضروری برای جلوگیری از اشتباهات مشابه در آینده خواهند بود. در نهایت، این فرآیند به هوش مصنوعی کمک میکند تا به یک ابزار دقیقتر و قابلاعتمادتر تبدیل شود، بهویژه در مواجهه با پرسشهای پیچیده.






